Transactional support for inter-task co-ordination within long-lived distributed applications
Santosh K. Shrivastava and Stuart M. Wheater
Department of Computing Science, Newcastle University,
Newcastle upon Tyne, NE1 7RU, England.
Introduction
We consider applications in the Internet/Web environment. The types of applications we have in mind are to do with the automation of so called 'business processes' of organizations that are increasingly using the Internet for their day to day functioning. The domain of electronic commerce is a good example: here automation of business processes would include system support to help consumer-to-business as well as business-to-business interactions for buying and selling of goods. Unfortunately, the Internet frequently suffers from failures which can affect both the performance and integrity of applications run over it.
A number of factors need to be taken into account in order to make these applications fault-tolerant. First, most such applications are rarely built from scratch; rather they are constructed by composing them out of existing applications and protocols. It should therefore be possible to compose an application out of component applications in a uniform manner, irrespective of the languages in which the component applications have been written and the operating systems of the host platforms. Application composition however must take into account individual site autonomy and privacy requirements. Second, the resulting applications can be very complex in structure, containing many temporal and data-flow dependencies between their constituent applications. However, constituent applications must be scheduled to run respecting these dependencies, despite the possibility of intervening processor and network failures. Third, the execution of such an application may take a long time to complete, and may contain long periods of inactivity (minutes, hours, days, weeks etc.), often due to the constituent applications requiring user interactions. It should be possible therefore to reconfigure an application dynamically because, for example, machines may fail, services may be moved or withdrawn and user requirements may change. Fourth, facilities are required for examining the application’s execution history (e.g., to be able to settle disputes). So, a durable ‘audit trail’ recording the interactions between component applications needs to be maintained. Taken together, these are challenging requirements to meet!
Distributed objects plus ACID transactions provide a foundation for building high integrity applications. However, it has long been realised that ACID transactions by themselves are not adequate for structuring long-lived applications [1]. Top-level transactions are most suitably viewed as "short-lived" entities, performing stable state changes to the system. Long-lived top-level transactions may reduce the concurrency in the system to an unacceptable level by holding on to resources for a long time; further, if such a transaction aborts, much valuable work already performed could be undone. In short, if an application is composed as a collection of transactions, then during run time, the entire activity representing the application in execution is frequently required to relax some of the ACID properties of the individual transactions. The entire activity can then be viewed as a non-ACID ‘extended transaction’. Much research work has been done on developing extended transaction models [e.g. 2]. Nevertheless, most of these techniques have not found any widespread usage, the main reason being lack of flexibility [3].
As observed in [3], transactional workflow systems with scripting facilities for expressing the composition of an activity (a business process) offer a flexible way of building application specific extended transactions. Our approach is in the similar vain: we have implemented an application composition and execution environment as a transactional workflow system that enables sets of inter-related tasks to be carried out and supervised in a dependable manner. Currently available workflow systems are not scalable, as their structure tends to be monolithic. Further, they offer little support for building fault-tolerant applications, nor can they inter-operate, as they make use of proprietary platforms and protocols. Our system represents a significant departure from these; our system architecture is decentralized and open: it has been designed and implemented as a set of CORBA services to run on top of a given ORB [4].
An overview of the transactional workflow system
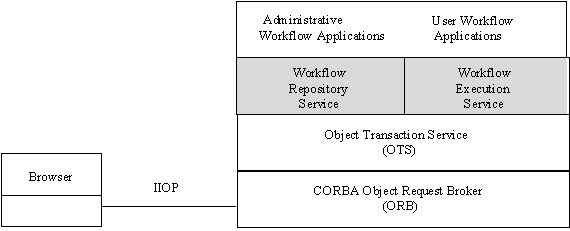
The workflow system’s structure is shown in fig. 1. Here the big box represents the structure of the entire distributed workflow system (and not the software layers of a single node); the small box represents any node with a Java capable browser. The most important components of the system are the two transactional services, the workflow repository service and the workflow execution service. These two facilities make use of the CORBA Object Transaction Service (OTS). In our system, application control and management tools required for functions such as monitoring and dynamic reconfiguration etc., (collectively referred to as administrative applications) themselves can be implemented as workflow applications. Thus the administrative applications can be made fault-tolerant without any extra effort. Graphical user interface to the these administrative applications has been provided by making use of Java applets which can be loaded and run by any Java capable Web browser.
Fig. 1: Workflow management system structure.
Workflow Repository Service: The repository service stores workflow schemas and provides operations for initializing, modifying and inspecting schemas. A schema is represented according to the model briefly discussed below in terms of tasks, compound tasks, genesis tasks and dependencies. We have designed a scripting language that provides high-level notations (textual as well graphic) for the specification of schemas. The scripting language has been specifically designed to express task composition and inter-task dependencies of fault-tolerant distributed applications whose executions could span arbitrarily large durations [5]. We next describe the task model that enable flexible ways of composing an application
Tasks are ‘wrapper’ objects to real application tasks. A task is modelled as having a set of input sets and a set of output sets. In fig. 2, task t
i is represented as having two input sets I1 and I2, and two output sets O1 and O2. A task instance begins its life in a wait state, awaiting the availability of one of its input sets. The execution of a task is triggered (the state changes to active) by the availability of an input set, only the first available input set will trigger the task, the subsequent availability of other input sets will not trigger the task (if multiple input sets became available simultaneously, then the input set with the highest priority is chosen for processing). For an input set to be available it must have received all of its constituent input objects (i.e., indicating that all dataflow and notification dependencies have been satisfied). For example, in fig. 2, input set I1 requires three dependencies to be satisfied: objects i1 and i2 must become available (dataflow dependencies) and one notification must be signalled (notifications are modelled as data-less input objects). A given input can be obtained from more than one source (e.g., three for i3 in set I2). If multiple sources of an input become available simultaneously, then the source with the highest priority is selected.A task terminates (the state changes to complete) producing output objects belonging to exactly one of a set of output sets (O
1 or O2 for task ti). An output set consists of a (possibly empty) set of output objects (o2 and o3 for output set O2). Task instances manipulate references to input and output objects. A task is associated with one or more implementations (application code); at run time, a task instance is bound to a specific implementation.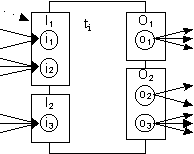
Fig. 2: A task
A schema indicates how the constituent tasks are ‘connected’. We term a source of an input an input alternative. In fig. 3 all the input alternatives of a task t
3 are labelled S1, S2, …, S8. An example of an input having multiple input alternatives is i1, this has two input alternatives S1 and S2. Note that the source of an input alternative could be from an output set (e.g., S4) or from an input set (e.g., S7); the latter represents the case when an input is consumed by more than one task.The notification dependencies are represented by dotted lines, for example, S
5 is a notification alternative for notification dependency n1.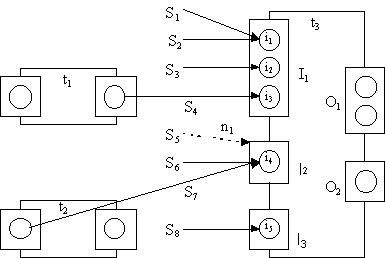
Fig. 3: A Workflow schema indicating inter-task dependencies.
To allow applications to be recursively structured, the task model allows a task to be realized as a collection of tasks, this task is called a compound task. A task can either be a simple task (primitive task) or a compound task composed from simple and compound tasks.
The task model also supports a specialised form of compound task called a genesis task to specify workflow applications that contain recursive executions [4, 6]. Its main purpose is to enable dynamic (on demand) instantiation of schema; this provides an efficient way of managing a very large workflow, as only those parts that are strictly needed are instantiated.
In summary, the task model has the following notable features:
·
Alternative input sources: A task can acquire a given input from more than one source. This is the principal way of introducing redundant data sources for a task and for a task to control input selection.·
Alternative outputs: A task can terminate in one of several output states, producing distinct outcomes. Assume that a task is an atomic transaction that transfers a sum of money from customer account A to customer account B by debiting A and crediting B. Then one outcome could be the result of the task committing and the other outcome could an indication that the task has aborted.·
Compound tasks: A task can be composed from other tasks. This is the principal way of composing an application out of other applicationsWorkflow Execution Service: The workflow execution service coordinates the execution of a workflow instance: it records inter-task dependencies of a schema in persistent atomic objects and uses atomic transactions for propagating coordination information to ensure that tasks are scheduled to run respecting their dependencies. The dependency information is maintained and managed by task controllers. Each task within a workflow application has a single dedicated task controller. The purpose of a task controller is to receive notifications of outputs of other task controllers and use this information to determine when its associated task can be started. The task controller is also responsible for propagating notifications of outputs of its task to other interested task controllers. Each task controller maintains a persistent, atomic object, TaskControl that is used for recording task dependencies. The structure is shown in fig. 4. For example, task controller tc3 will co-ordinate with tc1 and tc3 to determine when t3 can be started and propagate to tc4 and tc5 the results of t3.
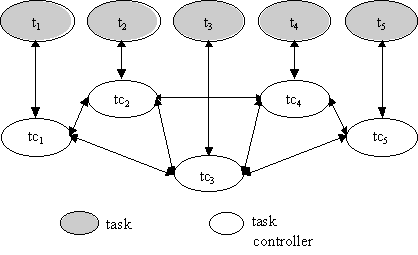
Fig. 4: Tasks and task controllers.
In short, our system provides a very flexible and dependable task coordination facility that need not have any centralized control. Because the system is built using the underlying transactional layer, no additional recovery facilities are required for reliable task scheduling: provided failed nodes eventually recover and network partitions eventually heal, task notifications will be eventually completed. In addition, the system automatically records the application's execution history (audit trail): this is maintained in the committed states of TaskControl objects of the application.
Another important aspect of our system that is discussed in detail elsewhere is that the system directly provides support for dynamic modification of workflows [6]. Briefly, the TaskControl objects maintain the inter-task dependency information of an application (as indicated above) and make this information available through transactional operations for performing changes (such as addition and removal of tasks as well as addition and removal of dependencies between tasks). The use of transactions ensures that changes to schemas and instances are carried out atomically with respect to normal processing.
Concluding Remarks
Currently available workflow systems are not scalable, as their structure tends to be monolithic. Further, they offer little support for building fault-tolerant distributed applications. System such as ours, Coyote [7] and ORBWork [8] represent new generation of (research) systems that can work in distributed environments and provide support for fault tolerance.
Our system has been structured to provide dependability at application level and system level. Support for application level dependability has been provided through flexible task composition discussed earlier that enables an application builder to incorporate alternative tasks, compensating tasks, replacement tasks etc., within an application to deal with a variety of exceptional situations. Support for system level dependability has been provided by recording inter-task dependencies in transactional shared objects and by using transactions to implement the delivery of task outputs such that destination tasks receive their inputs despite finite number of intervening machine crashes and temporary network related failures; this also provides a durable audit trail of task interactions. Thus our system naturally provides a fault-tolerant ‘job scheduling’ environment that maintains a durable history of application interactions.
The system described here has been fully implemented.
Acknowledgements
This work has been supported in part by grants from Nortel Technology and Engineering and Physical Sciences Research Council, ESPRIT LTR Project C3DS (Project No. 24962) and ESPRIT Project MultiPLECX (Project No. 26810).
References
[1] J. N. Gray, "The transaction concept: virtues and limitations", Proceedings of the 7th VLDB Conference, September 1981, pp. 144-154.
[2] A. K. Elmagarmid (ed), "Transaction models for advanced database applications", Morgan Kaufmann, 1992.
[3] G. Alonso, D. Agrawal, A. El Abbadi, M. Kamath, R. Gunthor and C. Mohan, "Advanced transaction models in workflow contexts", Proc. of 12th Intl. Conf. on Data Engineering, New Orleans, March 1996.
[4] S.M. Wheater, S.K. Shrivastava and F. Ranno "A CORBA Compliant Transactional Workflow System for Internet Applications ", Proc. Of IFIP Intl. Conference on Distributed Systems Platforms and Open Distributed Processing, Middleware 98, (N. Davies, K. Raymond, J. Seitz, eds.), Springer-Verlag, London, 1998, ISBN 1-85233-088-0, pp. 3-18.
[5] F. Ranno, S.K Shrivastava and S.M. Wheater, "A Language for Specifying the Composition of Reliable Distributed Applications", 18th IEEE Intl. Conf. on Distributed Computing Systems, ICDCS’98, Amsterdam, May 1998, pp. 534-543.
[6] S K Shrivastava and S M Wheater, "Architectural Support for Dynamic Reconfiguration of distributed workflow Applications", IEE Proceedings – Software, Vol. 145, No. 5, October 1998, pp. 155-162.
[7] A. Dan and F. Parr, "The COYOTE Approach for Network Centric Service Applications: Conversational Service Transactions, a Monitor and an Application Style", Proc. of 7th Intl. Workshop on High Perf. Transaction Systems, Asilomar, California, Sept 1997, pp. 23-48.
[8] S. Das, K. Kochut, J. Miller, A. Seth and D. Worah, "ORBWork: A Reliable Distributed CORBA-based Workflow Enactment System for METEOR2", Tech. Report No. UGA-CS-TR 97-001, Dept. of Computer Science, University of Georgia, Feb. 1997.