Experiences and Lessons from the Divx TPS
HPTS Position Paper
This paper describes the architecture of the Divx TPS and the lessons we’ve learned about the design, development, and operation of a transaction processing system. The Divx TPS has been in use since November of 1997. It’s functions span the gamut from a rental billing system to systems that control manufacturing lines. The TPS currently supports hundreds of thousands of customers and transactions on millions of Divx-DVD discs.
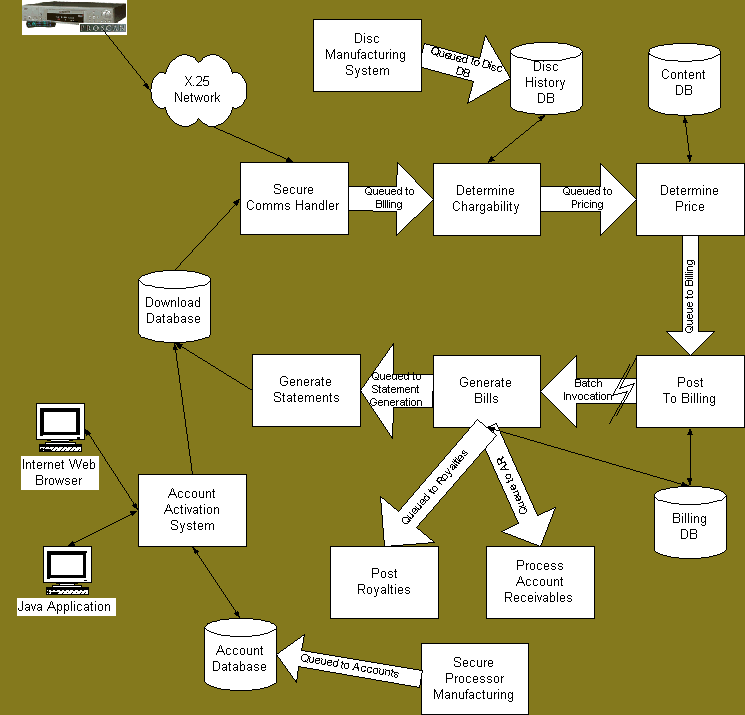
The architecture of the Divx TPS is primarily a transactional pipe-and-filter architecture. Player activity is reported to the TPS via secure communications where it is stored in a queue for later processing. During the secure session the TPS also downloads to the player new title entries and billing statements. Offline from the player communications session the activity is piped to the billing subsystem via a transactional queuing system. The billing system calculates the bill for the player activity and charges the customer’s credit card. Due to the cyclic nature of billing some aspects of this subsystem operate as batch processing.
The diagram below illustrates the general flow of the TPS. Many details have been removed for clarity. The main flow of the TPS revolves around a circle of processing that comprises our video rental business. The circle is fed primarily by 3 entities. DVD Players sending play journals for billing. Disc manufacturers sending logs of discs created. And the security system sending logs of new security devices created. All of these inputs into the circle are based on the pipe-and-filter architecture.
The pipe-and-filter architecture has proven to be an extremely flexible structure for the operation of the business. We have, on several occasions, altered queue flows, added inputs, added queue outputs with no impact on existing application programs. A primary examples is the addition of our data warehouse. The warehouse was brought online after the national launch of Divx. Much of the data for the warehouse is copied from queues within the system and piped to the warehouse transparent to the sending or receiving applications which typically deal with the data. We have built into the architecture the ability to grow in capacity and functionality transparently to the existing applications. We can selectively by application increase the processing capacity by adding additional processing agents, adding CPUs or IO channels, adding new machines, and adding whole new cells. These options, and our ability to mix and match them, provide sufficient flexibility, with zero impact on application code, to grow our TPS to support millions of customers.
The pipe-and-filter architecture is weakest when dealing with the interactive nature of a customer support call center. When customers call our call center to activate a player they expect those changes to occur immediately. We have had to bypass the pipe-and-filter paradigm in several places when dealing with player activation. Yet, we must still deal with the pipe-and-filter nature of the bulk of the TPS. This paradox has produced some tortured logic in a subsystem critical to the ongoing growth of the business.
The Divx TPS is based on common off the shelf products. At the onset of the project our executive management dictated that we were to use no exotic hardware or software within the TPS. The underlying operating system is Sun Solaris. The databases are implemented using Informix 7.3. The TP monitor we choose was Encina. We use Encina’s RQS queuing facility as our method of piping data across the system. We are using the slightly older version of Encina that utilizes DCE as the underlying transport method, no CORBA yet. The majority of the applications were developed in house with the exception of order processing and warehouse management (not shown on the diagram above). Additionally, we constructed several hardware components internal to the DVD players and within the TPS, which are required for secure communications.
Due to a sudden requirement to perform extensive load testing we quickly purchased hardware to run the production systems. What should have been done in two months was given 1 week. Overriding philosophy: ‘Aim for the fence.’
Developed a benchmark to simulate the load of 700,000 players. We proved that our implementation was more than capable of handling this load with early versions of our application software.
Immediately upon completion of the load tests we reinstalled the systems using more current application software and real data with which to begin an in-house beta test of all of our business processes.
Executed a business beta test with approximately 100 test customers. We spent many late nights working strange, never before seen, bugs out of the system.
Reset most of the data and installed many new application versions in preparation for real paying customers.
Opened our ‘doors’ for business in Richmond, VA, and San Francisco, CA.
Swung the ‘doors’ open wide for customers all across the United States of America.
In every situation where we have permitted an application subsystem to bend the rules of the architecture we have suffered. A prime example of this situation is our billing system, which mixes a hybrid of pipe-and-filter and sequential batch processing. The system operates smoothly and efficiently up until it hits a seemingly artificial roadblock wherein batch processing takes over. The batch flow causes spikes in the subsequent workload. The processing power needed to handle the peak load conditions appears to be far greater than what would be required if performed in a more workflow manner.
Additionally, contention and concurrency problems are more frequent. In the pipe-and-filter mode the processing requirements are throttled by the overall input volumes coming into the TPS from external sources. In batch mode the system is driven to process data at it’s maximum rate. In the full throttle state it is more likely that processing agents will contend over row or index locks. Additionally, running in the full throttle mode increases the probability of starving critical background tasks of necessary resources.
In the initial production phase of the TPS we took the approach of monitoring application server error logs to detect system problems. This approach proved to be flawed. The application servers were frequently unable to accurately detect and report when their required resources were unavailable. Furthermore, the servers logged many messages about business logic problems or status thereby overwhelming the meager number of actual system issues encountered. It became a search for a needle in a haystack.
We have since revamped our system monitoring such that the monitor program watches the critical resources directly and notify the support staff directly. The monitor performs application-like work (i.e., inserting rows in a database or elements into a queue) and examines operating system level resources (swap, disk space, CPU utilization, etc).
The revamped system monitors have reduced the mean time to repair of the system problems that have occurred. In a distributed transaction system the application reporting the problem may be geographically distant or logically remote from the root cause of the problem. Depending on application reporting required support staff to follow the flow of the application through the system to manually examine its required resources until they located the offending resource. This process took time and experience that was not always available during a system crisis.
The current pool of executive managers have been sold a bill-of-goods by the industry and the press that any competent teenager can whip out a highly valuable computer system at the drop of a hat. We in the industry know this to be a myth. Building reliable, stable, and fully functional systems requires a regimented design, development, testing, and operational methodology; all of which costs time and money. One of on going struggles has been to set management expectations as to the complexity involved in building a system.
We have attempted to guide management expectations by getting early agreement to well constructed requirements. The process generally starts as the executive makes a request which may be in the form a seriously thought out aspect of the business strategy or a brainstormed idea. The technical analysts then craft a set of requirements describing what the new functionality should do. These requirements, and outstanding issues, are reviewed by a wide range of business and technical leadership and finally presented to the executives for approval. The requirements are usually accompanied by a project plan which estimates the amount of time and effort required to complete the project when taken in perspective with all of the other projects currently tasked to the departments. It is then up to the executive to alter priorities or, in some cases, cancel the project.
Many of our technical staff came from smaller, two-tier client server, environments that had very loose controls. It was a cultural shift for them to operate in an environment where they were no longer the lead singer, but just another member of a choir. In a system whose composition has evolved over many years and has a conglomeration of different architectures and technologies it is easier to survive cowboy implementations. But, in a system with consistent architecture and technology developers are more apt to create applications that graze other systems. The result is an application with many more interactions than were possible in earlier, inconsistent systems. Hence the need for greater change management; one ‘minor’ change to your system may have impacts you do not readily see, but will be exposed when the proposed change is brought into a public approval process.
Early on in our implementation, before the initial load tests, we implemented a strict separation of development from testing from production with ample documentation required for each transition. Many of the developers complained vociferously about the constraints, but the results have been a system whose behavior can be predicted and scheduled from day-to-day.
Early on in the architecture design phase of the system we were instructed to design for success. This philosophy has had two seemingly contradictory impacts on our operation.
The first impact is that the system appears to be much more complex then it needs to be. Much of the complexity comes from designing a system to be expandable and extensible without re-implementation or redesign. The result is a system that we can grow to very large capacity without rewriting a single line of code. System growth for the next several years can be handled exclusively by configuration changes and the addition of compute power and IO bandwidth.
The second impact is that the system exists in production in a form very close to that which was load tested. The development staff now is available for functionality growth rather than dealing with capacity growth. The administrative staff, and to a smaller extent the architectural staff, are responsible for insuring adequate capacity.